Ce document fait suite au support de cours consacré aux "Perceptrons simples et multicouches" et au tutoriel sur les "Packages R pour le Deep Learning - Perceptrons". L'objectif est de montrer un processus complet d'analyse prédictive à l'aide de successions de commandes simples sous Python : importer les données, les préparer ; construire et configurer le réseau ; estimer ses coefficients (poids synaptiques) à partir d'un ensemble de données étiquetées ; prédire sur un second échantillon, soit aux fins de déploiement, soit aux fins d'évaluation des performances.
La tâche est en théorie relativement aisée. Le véritable enjeu pour nous est d'identifier sans ambiguïtés, d'une part les bonnes commandes, d'autre part les paramètres idoines pour construire précisément le réseau que nous souhaitons appliquer sur les données. En pratique, ce n'est pas si évident que cela parce qu'identifier de la documentation pertinente sur le web n'est pas toujours facile. On retrouve souvent le même tutoriel avec la sempiternelle base MNIST, qui est littéralement accommodée à toutes les sauces. Pouvoir généraliser la démarche à d'autres bases devient une vraie gageure. J'espère y arriver en schématisant au mieux les étapes, et surtout en donnant au lecteur la possibilité de faire le parallèle avec la même mission réalisée sous R.
Nous étudierons les packages "scikit-learn", "keras / tensorflow" et "h2o". Nous dirons un mot également des librairies "MXNET", "PyTorch" et "caffe".
Mots-clés : packages python, deep learnin, perceptron simple, perceptron multicouche, scikit-learn, keras, tensorflow, h2o, mxnet, pytorch, caffe, réseaux de neurones
Didacticiel : Perceptrons - Packages Python
Données et programme Python : spam dataset python
Références :
Tutoriel Tanagra, "Deep Learning : perceptrons simples et multicouches", novembre 2018.
lundi 24 décembre 2018
dimanche 16 décembre 2018
Packages R pour le Deep Learning
Ce tutoriel fait suite au support de cours consacré aux perceptrons simples et multicouches. L'objectif est d'explorer le mode opératoire et l'efficacité des différents packages qui proposent la méthode.
Notre schéma de travail sera relativement classique s'agissant d'un contexte d'analyse prédictive. Nous importons une base de données, nous la subdivisons en échantillons d'apprentissage et de test. Nous standardisons les variables avec une subtilité importante que l'on précisera. Puis, pour chaque package, nous implémenterons un perceptron multicouche avec 1 seule couche cachée à 2 neurones (ce n'est pas de l'humour...) dont nous évaluerons les performances prédictives. Certains packages proposent des fonctionnalités additionnelles. Nous essayerons de les cerner.
Mots-clés : package R, logiciel R, nnet, neuralnet, h2o, rsnns, deepnet, keras, mxnet, perceptron simple, perceptron multicouche, réseaux de neurones, deep learning
Didacticiel : Perceptrons - Packages R
Données et programme R : spam dataset
Références :
Tutoriel Tanagra, "Deep learning : perceptrons simples et multicouches", novembre 2018.
Notre schéma de travail sera relativement classique s'agissant d'un contexte d'analyse prédictive. Nous importons une base de données, nous la subdivisons en échantillons d'apprentissage et de test. Nous standardisons les variables avec une subtilité importante que l'on précisera. Puis, pour chaque package, nous implémenterons un perceptron multicouche avec 1 seule couche cachée à 2 neurones (ce n'est pas de l'humour...) dont nous évaluerons les performances prédictives. Certains packages proposent des fonctionnalités additionnelles. Nous essayerons de les cerner.
Mots-clés : package R, logiciel R, nnet, neuralnet, h2o, rsnns, deepnet, keras, mxnet, perceptron simple, perceptron multicouche, réseaux de neurones, deep learning
Didacticiel : Perceptrons - Packages R
Données et programme R : spam dataset
Références :
Tutoriel Tanagra, "Deep learning : perceptrons simples et multicouches", novembre 2018.
dimanche 18 novembre 2018
Deep learning : perceptrons simples et multicouches
La vie est faite de bizarreries qui m’étonnent toujours. A mes débuts dans l’enseignement, les étudiants étaient très curieux de savoir ce qu’étaient ces fameux réseaux de neurones qui leur paraissaient tant mystérieux. Faute de disposer d’outils simples à utiliser (au milieu des années 90), je l’avais programmé dans SIPINA et j’avais monté un cours dessus, en me focalisant sur l’analyse prédictive avec le perceptron, simple et multicouche. Au fil des années, d’autres approches sont devenues plus "populaires" (oui, même dans le domaine scientifique, ça existe), les SVM (suppport vector machine) ou encore les technologies bagging, random forest, boosting. L’intérêt des étudiants s’étant délité, j’ai rangé au placard ma séance consacrée au perceptron dans mon cours de machine learning (qui s’appelait data mining à l’époque, conséquence d’un autre phénomène de mode aussi).
Puis est venue la vague du deep learning. Les étudiants sont revenus à la charge. J’ai cru à une blague tout d’abord quand j’ai lu les premiers articles qui en parlaient. Ils s’agiraient de réseaux avec plusieurs couches pour faire de l’apprentissage profond. Ah bon ? Ce n’est pas ce que l’on avait avec les perceptrons ? Et ce depuis bien longtemps déjà ! Passé ce premier instant de scepticisme, je me suis dit que cet engouement devait reposer sur des bases quand même un peu plus solides, et j’ai un peu creusé l’affaire. Je me suis rendu compte qu’il y avait matière à proposer des choses intéressantes dans mes enseignements. Je suis donc parti dans l’idée de réaliser une série de supports sur le sujet, à commencer par dépoussiérer mon cours sur les perceptrons, que j’ai fait évoluer à la lumière des « nouveautés » proposées dans les bibliothèques de calcul qui font foi, en particulier sous R et sous Python.
Puis est venue la vague du deep learning. Les étudiants sont revenus à la charge. J’ai cru à une blague tout d’abord quand j’ai lu les premiers articles qui en parlaient. Ils s’agiraient de réseaux avec plusieurs couches pour faire de l’apprentissage profond. Ah bon ? Ce n’est pas ce que l’on avait avec les perceptrons ? Et ce depuis bien longtemps déjà ! Passé ce premier instant de scepticisme, je me suis dit que cet engouement devait reposer sur des bases quand même un peu plus solides, et j’ai un peu creusé l’affaire. Je me suis rendu compte qu’il y avait matière à proposer des choses intéressantes dans mes enseignements. Je suis donc parti dans l’idée de réaliser une série de supports sur le sujet, à commencer par dépoussiérer mon cours sur les perceptrons, que j’ai fait évoluer à la lumière des « nouveautés » proposées dans les bibliothèques de calcul qui font foi, en particulier sous R et sous Python.
Mots-clés : réseaux de neurones, deep learning, perceptron simple, perceptron multicouche, keras, scikit-learn, logiciel R, python, apprentissage supervisé, analyse prédictive, machine learning
Support de cours : Perceptrons simples et multicouches
Références :
Wikipedia, "Perceptron".
mardi 6 novembre 2018
Ateliers Master SISE : outils de la Dataviz
Comme tous les ans, à la rentrée universitaire, je demande aux étudiants du Master SISE d’assurer des ateliers techniques destinés à former leurs propres collègues. Cette année, mon choix s’est porté sur les outils de la Dataviz (de Reporting) : Power BI (version gratuite), Google Data Studio et D3.js.
Bien sûr, avec 3 heures pour chaque outil (1h30 initiation [1], 1h30 perfectionnement [2]), on peut difficilement les étudier en profondeur. Mais par expérience, je sais que franchir la barrière à l’entrée est très souvent le principal enjeu de l’autoformation. Lorsque l’apprenant ne sait pas par quel bout commencer, il se décourage vite souvent. Pouvoir passer cet écueil est donc primordial, et c’est justement l’objectif des ateliers qu’ont préparé les étudiants, avec des étapes clés basiques : comment importer et manipuler ses données, comment créer un premier dashboard, quelles sont les principales fonctionnalités (représentations graphiques, tableaux, etc.), qu’est-ce que l’on peut attendre de l’outil globalement… Ces ateliers jouent parfaitement leur rôle dans cette optique. Par la suite, une fois que nous avons mis le pied à l’étrier, il nous appartient d’aller plus loin par nous-même.
Les fichiers ci-dessous comprennent : les supports de présentation, les sujets des exercices, les données et/ou corrigés (PDF), le corrigé sous forme de tutoriel vidéo.
Merci aux étudiants pour cet excellent travail qui profitera à tout le monde. La Dataviz est une compétence connue et reconnue dans le monde de la data. Il suffit de consulter les offres d’emploi que l’on trouve sur le site de l’APEC par exemple pour s'en convaincre (Dataviz).
Bien sûr, avec 3 heures pour chaque outil (1h30 initiation [1], 1h30 perfectionnement [2]), on peut difficilement les étudier en profondeur. Mais par expérience, je sais que franchir la barrière à l’entrée est très souvent le principal enjeu de l’autoformation. Lorsque l’apprenant ne sait pas par quel bout commencer, il se décourage vite souvent. Pouvoir passer cet écueil est donc primordial, et c’est justement l’objectif des ateliers qu’ont préparé les étudiants, avec des étapes clés basiques : comment importer et manipuler ses données, comment créer un premier dashboard, quelles sont les principales fonctionnalités (représentations graphiques, tableaux, etc.), qu’est-ce que l’on peut attendre de l’outil globalement… Ces ateliers jouent parfaitement leur rôle dans cette optique. Par la suite, une fois que nous avons mis le pied à l’étrier, il nous appartient d’aller plus loin par nous-même.
Les fichiers ci-dessous comprennent : les supports de présentation, les sujets des exercices, les données et/ou corrigés (PDF), le corrigé sous forme de tutoriel vidéo.
Merci aux étudiants pour cet excellent travail qui profitera à tout le monde. La Dataviz est une compétence connue et reconnue dans le monde de la data. Il suffit de consulter les offres d’emploi que l’on trouve sur le site de l’APEC par exemple pour s'en convaincre (Dataviz).
| Thèmes | Présentations | Exercices | Dataset / Corrigés | Tutoriels |
|---|---|---|---|---|
| Power BI 1 |  |  |  |  |
| Power BI 2 | | | | |
| Data Studio 1 | | | | |
| Data Studio 2 | | | | |
| D3.js 1 | | |  | |
| D3.js 2 | | | | |
vendredi 14 septembre 2018
LibreOffice Base
J’ai mis en ligne récemment un module de remise à niveau pour les candidats au Master SISE dédié au langage SQL (structured query language). Les exercices ont été préparés par les étudiants de la promotion 2017-2018. Ils ont choisi de privilégier le SGDB (système de gestion de bases de données) Microsoft Access parce qu’il est installé par défaut dans les salles machines de notre Université.
En réalité, les exercices sont génériques (parce que le langage SQL l’est ! même s’il peut y avoir des spécificités parfois selon les outils), ils sont réalisables sous tout autre SGBD. Et c’est une bonne chose parce que tout le monde n’a pas accès à Access, qui est payant rappelons-le. Nous pouvons notamment utiliser l’outil Base de la suite bureautique LibreOffice. Dans ce tutoriel, je montre comment créer une base via l’importation de données contenues dans des fichiers Excel, comment établir les liens entre les tables générées, puis initier des requêtes mono ou multi-tables.
En réalité, les exercices sont génériques (parce que le langage SQL l’est ! même s’il peut y avoir des spécificités parfois selon les outils), ils sont réalisables sous tout autre SGBD. Et c’est une bonne chose parce que tout le monde n’a pas accès à Access, qui est payant rappelons-le. Nous pouvons notamment utiliser l’outil Base de la suite bureautique LibreOffice. Dans ce tutoriel, je montre comment créer une base via l’importation de données contenues dans des fichiers Excel, comment établir les liens entre les tables générées, puis initier des requêtes mono ou multi-tables.
Mots-clés : base de données, langage SQL, libreoffice, base, microsoft access
Didacticiel : LibreOffice Base
Données : BD + Fichiers Excel sources
Références :
LibreOffice Base, https://fr.libreoffice.org/discover/base/
Master SISE : Remise à niveau - SQL
mercredi 12 septembre 2018
Master SISE - Remise à niveau - SQL
Les données sont la principale matière première de la data science, lesquelles sont souvent stockées dans des bases de données relationnelles. Savoir les manipuler correctement est par conséquent une compétence fondamentale pour nous.
Il y a deux phases dans l’appréhension des bases de données. La première est leur conception à partir des informations existantes. Il s’agit de les collecter, de les recenser et de proposer une organisation sous forme d’une collection de tables, reliées entre elles. La méthode MERISE est certainement une des approches les plus populaires pour les élaborer rationnellement (ex. Idriss NEUMANN, "Initiation à la conception de bases de données relationnelles avec MERISE").
Le seconde phase consiste à les exploiter en insérant des données dans les tables, effectuer des mises à jour et, très souvent, réaliser de requêtes d’extraction pour récupérer les données disponibles correspondant à certaines conditions. Le langage SQL (structured query language) est l’outil privilégié pour cette tâche. On peut vouloir obtenir par exemple la liste des clients et les montants d’achats des personnes qui sont venus dans tels magasins d’une grande chaîne de distribution durant telle période. Une instruction SQL simple permet de le faire rapidement et ainsi d’initier par la suite les analyses qui conviennent. De fait, SQL apparaît systématiquement dans le top des outils couramment utilisés par les data scientists (Sondage KdNuggets, Mai 2018).
Ce thème de remise à niveau est plutôt consacré à la seconde phase. La base est considérée comme conçue, les tables sont pourvues de données (il faudra quand même importer les données à partir de fichiers Excel au préalable). L’objectif des exercices est de familiariser l’apprenant aux principales commandes SQL.
Particularité importante de ce thème, les supports de cours et les exercices ont été conçus par les étudiants même du Master SISE, promotion 2017-2018. Je les en remercie.
Document principal : SQL - Trame
Outil : Microsoft ACCESS ou LibreOffice BASE
Exercice 1 : SQL Niveau 1, cours, exercices, données
Exercice 2 : SQL Niveau 2, cours, exercices
Il y a deux phases dans l’appréhension des bases de données. La première est leur conception à partir des informations existantes. Il s’agit de les collecter, de les recenser et de proposer une organisation sous forme d’une collection de tables, reliées entre elles. La méthode MERISE est certainement une des approches les plus populaires pour les élaborer rationnellement (ex. Idriss NEUMANN, "Initiation à la conception de bases de données relationnelles avec MERISE").
Le seconde phase consiste à les exploiter en insérant des données dans les tables, effectuer des mises à jour et, très souvent, réaliser de requêtes d’extraction pour récupérer les données disponibles correspondant à certaines conditions. Le langage SQL (structured query language) est l’outil privilégié pour cette tâche. On peut vouloir obtenir par exemple la liste des clients et les montants d’achats des personnes qui sont venus dans tels magasins d’une grande chaîne de distribution durant telle période. Une instruction SQL simple permet de le faire rapidement et ainsi d’initier par la suite les analyses qui conviennent. De fait, SQL apparaît systématiquement dans le top des outils couramment utilisés par les data scientists (Sondage KdNuggets, Mai 2018).
Ce thème de remise à niveau est plutôt consacré à la seconde phase. La base est considérée comme conçue, les tables sont pourvues de données (il faudra quand même importer les données à partir de fichiers Excel au préalable). L’objectif des exercices est de familiariser l’apprenant aux principales commandes SQL.
Particularité importante de ce thème, les supports de cours et les exercices ont été conçus par les étudiants même du Master SISE, promotion 2017-2018. Je les en remercie.
Document principal : SQL - Trame
Outil : Microsoft ACCESS ou LibreOffice BASE
Exercice 1 : SQL Niveau 1, cours, exercices, données
Exercice 2 : SQL Niveau 2, cours, exercices
mardi 26 juin 2018
Pipeline sous Python - La méthode DISQUAL
En inventoriant le package « fanalysis » d’Olivier Garcia dédié à l’analyse factorielle (ACP, AFC et ACM) sous Python, mon attention a été attirée par l’outil Pipeline du package « scikit-learn » mis en avant lors de la présentation de l’ACM (analyse des correspondances multiples). Un Pipeline est un méta-opérateur qui permet d’enchaîner plusieurs calculs, pourvu que les classes mises à contribution implémentent les fonctions fit() (apprentissage) et transform() (projection). Les mécanismes de classes de Python et la forte cohérence des objets de « scikit-learn » font merveille ici. Cette notion d’opérateur encapsulant plusieurs autres qui s’exécutent séquentiellement n’est pas sans rappeler les metanodes dans des logiciels de data mining tels que Knime. J’avais pu en explorer le fonctionnement lors de la programmation de la validation croisée par exemple.
Nous nous appuierons sur l’étude de la méthode DISQUAL de Gilbert Saporta pour montrer l’intérêt de la classe Pipeline de « scikit-learn ». DISQUAL (discrimination sur variables qualitatives) permet de réaliser une analyse discriminante prédictive sur des variables explicatives qualitatives en faisant succéder deux techniques statistiques : dans un premier temps, une ACM est opérée sur les descripteurs, nous obtenons une description des données dans un espace factoriel ; dans un second temps, on lance une analyse discriminante linéaire (ADL), expliquant la variable cible à partir des facteurs de l’ACM. DISQUAL cumule un double avantage : elle rend réalisable l’analyse discriminante linéaire dans une configuration qu’elle ne sait pas appréhender nativement (explicatives qualitatives) ; on peut en moduler les propriétés de régularisation, et donc la robustesse au surapprentissage, en jouant sur le nombre de facteurs de l’ACM à retenir pour l’analyse discriminante.
On note surtout dans le contexte de ce tutoriel que DISQUAL est constituée deux techniques statistiques qui se succèdent (ACM + ADL). Elle se prête à merveille à l’utilisation de l'outil Pipeline.
Mots-clés : pipeline, scikit-learn, package fanalysis, disqual, acm, analyse des correspondances multiples, discrimination sur variables qualitatives, analyse discriminante
Composants Tanagra : MULTIPLE CORRESPONDANCE ANALYSIS, LINEAR DISCRIMINANT ANALYSIS
Didacticiel : Pipeline et DISQUAL
Données et programme : Pipeline et disqual - Python
Références :
Scikit-learn, "sklearn.pipeline.Pipeline".
LeMakiStatheux, "La méthode DISQUAL".
Nous nous appuierons sur l’étude de la méthode DISQUAL de Gilbert Saporta pour montrer l’intérêt de la classe Pipeline de « scikit-learn ». DISQUAL (discrimination sur variables qualitatives) permet de réaliser une analyse discriminante prédictive sur des variables explicatives qualitatives en faisant succéder deux techniques statistiques : dans un premier temps, une ACM est opérée sur les descripteurs, nous obtenons une description des données dans un espace factoriel ; dans un second temps, on lance une analyse discriminante linéaire (ADL), expliquant la variable cible à partir des facteurs de l’ACM. DISQUAL cumule un double avantage : elle rend réalisable l’analyse discriminante linéaire dans une configuration qu’elle ne sait pas appréhender nativement (explicatives qualitatives) ; on peut en moduler les propriétés de régularisation, et donc la robustesse au surapprentissage, en jouant sur le nombre de facteurs de l’ACM à retenir pour l’analyse discriminante.
On note surtout dans le contexte de ce tutoriel que DISQUAL est constituée deux techniques statistiques qui se succèdent (ACM + ADL). Elle se prête à merveille à l’utilisation de l'outil Pipeline.
Mots-clés : pipeline, scikit-learn, package fanalysis, disqual, acm, analyse des correspondances multiples, discrimination sur variables qualitatives, analyse discriminante
Composants Tanagra : MULTIPLE CORRESPONDANCE ANALYSIS, LINEAR DISCRIMINANT ANALYSIS
Didacticiel : Pipeline et DISQUAL
Données et programme : Pipeline et disqual - Python
Références :
Scikit-learn, "sklearn.pipeline.Pipeline".
LeMakiStatheux, "La méthode DISQUAL".
lundi 11 juin 2018
Analyses factorielles sous Python avec fanalysis
Je concluais mon précédent tutoriel sur l’ACP sous Python en espérant voir un jour des packages Python permettant de réaliser plus simplement (que sous ''scikit-learn''), plus efficacement, les analyses factorielles : ACP [analyse en composantes principales], mais pourquoi pas aussi l’AFC [analyse factorielle des correspondances] et l’ACM [analyse des correspondances multiples].
Mes voeux ont été devancés. Un de mes anciens étudiants du Master SISE, Olivier Garcia (SISE 1999-2000, ça remonte à quelques années …), m’indique qu’il a mis en ligne récemment un package qui permettent de réaliser ces analyses, avec toutes les fonctionnalités attendues de l’analyse de données à la française décrite dans les publications francophones qui font référence. Un grand Merci à lui !
Le package intitulé "fanalysis" est sous licence BSD-3 et peut se télécharger simplement en tapant en ligne de commande :
pip install fanalysis
Voici le lien vers le repo GitHub : https://github.com/OlivierGarciaDev/fanalysis
Ce package fanalysis poursuit un double objectif :
1) Permettre de réaliser des analyses factorielles dans un but descriptif. Il permet de produire simplement les statistiques principales : valeurs propres, coordonnées, contributions, cos2. Ces statistiques peuvent être exportées vers un DataFrame Pandas. En outre, divers outils graphiques sont proposés : valeurs propres, mapping factoriels, graphiques permettant de voir quelles lignes/colonnes présentent les plus fortes contributions/cos2 pour un axe donné...
2) Permettre d'utiliser les analyses factorielles en tant que méthodes de pre-processing dans des pipelines scikit-learn. On peut ainsi, par exemple, enchaîner une AFC multiple puis une régression logistique, et optimiser le nombre de facteurs pris en compte par validation croisée.
La docstring est en écrite globish, mais 3 tutos sont disponibles en français sur le repo GitHub, sous forme de notebooks :
Le package met à disposition des tests unitaires dont la philosophie générale est de comparer les sorties de ses méthodes avec celles du package R FactoMineR. Ouf, les tests s'avèrent concluant !
Le package fanalysis fonctionne avec des matrices denses en entrée.
Sur le plan technique, c'est la fonction svd() (décomposition en valeurs singulières) de numpy qui est au coeur des calculs.
Mots-clés : package fanalysis, python, acp, analyse en composantes principales, afc, analyse factorielle des correspondances, acm, analyse des correspondances multiples
Ouvrage de référence : "Pratique des Méthodes Factorielles avec Python", juillet 2020.
Site de référence : Cours Analyse Factorielle
Mes voeux ont été devancés. Un de mes anciens étudiants du Master SISE, Olivier Garcia (SISE 1999-2000, ça remonte à quelques années …), m’indique qu’il a mis en ligne récemment un package qui permettent de réaliser ces analyses, avec toutes les fonctionnalités attendues de l’analyse de données à la française décrite dans les publications francophones qui font référence. Un grand Merci à lui !
Le package intitulé "fanalysis" est sous licence BSD-3 et peut se télécharger simplement en tapant en ligne de commande :
pip install fanalysis
Voici le lien vers le repo GitHub : https://github.com/OlivierGarciaDev/fanalysis
Ce package fanalysis poursuit un double objectif :
1) Permettre de réaliser des analyses factorielles dans un but descriptif. Il permet de produire simplement les statistiques principales : valeurs propres, coordonnées, contributions, cos2. Ces statistiques peuvent être exportées vers un DataFrame Pandas. En outre, divers outils graphiques sont proposés : valeurs propres, mapping factoriels, graphiques permettant de voir quelles lignes/colonnes présentent les plus fortes contributions/cos2 pour un axe donné...
2) Permettre d'utiliser les analyses factorielles en tant que méthodes de pre-processing dans des pipelines scikit-learn. On peut ainsi, par exemple, enchaîner une AFC multiple puis une régression logistique, et optimiser le nombre de facteurs pris en compte par validation croisée.
La docstring est en écrite globish, mais 3 tutos sont disponibles en français sur le repo GitHub, sous forme de notebooks :
Le package met à disposition des tests unitaires dont la philosophie générale est de comparer les sorties de ses méthodes avec celles du package R FactoMineR. Ouf, les tests s'avèrent concluant !
Le package fanalysis fonctionne avec des matrices denses en entrée.
Sur le plan technique, c'est la fonction svd() (décomposition en valeurs singulières) de numpy qui est au coeur des calculs.
Mots-clés : package fanalysis, python, acp, analyse en composantes principales, afc, analyse factorielle des correspondances, acm, analyse des correspondances multiples
Ouvrage de référence : "Pratique des Méthodes Factorielles avec Python", juillet 2020.
Site de référence : Cours Analyse Factorielle
vendredi 8 juin 2018
ACP avec Python
J’ai déjà beaucoup donné pour l’analyse en composantes principales, sous forme de support de cours (ACP), de tutoriels pour Tanagra, pour Excel, pour R, ... mais jamais pour Python.
Il est temps d’y remédier. D’autant plus que l’affaire n’est pas si évidente finalement. J’ai choisi d’utiliser le package "scikit-learn" maintes fois cité sur le web. Je me suis rendu compte que la classe PCA effectuait les calculs essentiels effectivement, mais il nous appartenait ensuite de programmer tout le post-traitement, notamment les aides à l’interprétation. Je me suis retrouvé un peu dans la même situation qu’il y a presque 10 ans où je m’essayais à l’ACP sous R en utilisant la fonction basique princomp() du package "stats" (Mai 2009). Le tutoriel associé ainsi que notre support de cours nous serviront de repères tout au long de ce document.
Mots-clés : analyse en composantes principales, ACP, package scikit-learn, PCA
Didacticiel : ACP sous Python
Données et programme : Autos Python
Références :
Tutoriel Tanagra, "ACP avec Tanagra - Nouveaux outils", Juin 2012.
Tutoriel Tanagra, "Analyse en Composantes Principales avec R", Mai 2009.
Tutoriel Tanagra, "ACP avec R - Détection du nombre d'axes", Juin 2012.
Site de référence :
Cours Analyse Factorielle
Il est temps d’y remédier. D’autant plus que l’affaire n’est pas si évidente finalement. J’ai choisi d’utiliser le package "scikit-learn" maintes fois cité sur le web. Je me suis rendu compte que la classe PCA effectuait les calculs essentiels effectivement, mais il nous appartenait ensuite de programmer tout le post-traitement, notamment les aides à l’interprétation. Je me suis retrouvé un peu dans la même situation qu’il y a presque 10 ans où je m’essayais à l’ACP sous R en utilisant la fonction basique princomp() du package "stats" (Mai 2009). Le tutoriel associé ainsi que notre support de cours nous serviront de repères tout au long de ce document.
Mots-clés : analyse en composantes principales, ACP, package scikit-learn, PCA
Didacticiel : ACP sous Python
Données et programme : Autos Python
Références :
Tutoriel Tanagra, "ACP avec Tanagra - Nouveaux outils", Juin 2012.
Tutoriel Tanagra, "Analyse en Composantes Principales avec R", Mai 2009.
Tutoriel Tanagra, "ACP avec R - Détection du nombre d'axes", Juin 2012.
Site de référence :
Cours Analyse Factorielle
jeudi 24 mai 2018
Régressions ridge et elasticnet sous R
Ce tutoriel fait suite au support de cours consacré à la régression régularisée (RAK, 2018). Il vient en contrepoint au document récent consacré à la Régression Lasso sous Python. Nous travaillons sous R cette fois-ci et nous étudions les régressions ridge et elasticnet.
Nous nous situons dans le cadre de la régression logistique avec une variable cible qualitative binaire. Le contexte n’est pas favorable avec un échantillon d’apprentissage constitué de n_train = 200 observations et p = 123 descripteurs, dont certains sont en réalité des constantes. Les propriétés de régularisation de ridge et elasticnet devraient se révéler décisives. Encore faut-il savoir / pouvoir déterminer les valeurs adéquates des paramètres de ces algorithmes. Ils pèsent fortement sur la qualité des résultats.
Nous verrons comment faire avec les outils à notre disposition. Nous utiliserons les packages ‘’glmnet’’ et ‘’tensorflow / keras’’. Ce dernier tandem a été présenté plus en détail dans un précédent document (Avril 2018). Il faut s’y référer notamment pour la partie installation qui n’est pas triviale.
Mots-clés : régression ridge, régression elasticnet, package glmnet, package tensorflow, package keras, ridge path, elasticnet path, coefficient de pénalité, validation croisée
Didacticiel : Ridge et elasticnet sous R
Données et programme : Adult dataset
Références :
Rakotomalala R., "Régression régularisée - Ridge, Lasso, Elasticnet", Mai 2018.
Nous nous situons dans le cadre de la régression logistique avec une variable cible qualitative binaire. Le contexte n’est pas favorable avec un échantillon d’apprentissage constitué de n_train = 200 observations et p = 123 descripteurs, dont certains sont en réalité des constantes. Les propriétés de régularisation de ridge et elasticnet devraient se révéler décisives. Encore faut-il savoir / pouvoir déterminer les valeurs adéquates des paramètres de ces algorithmes. Ils pèsent fortement sur la qualité des résultats.
Nous verrons comment faire avec les outils à notre disposition. Nous utiliserons les packages ‘’glmnet’’ et ‘’tensorflow / keras’’. Ce dernier tandem a été présenté plus en détail dans un précédent document (Avril 2018). Il faut s’y référer notamment pour la partie installation qui n’est pas triviale.
Mots-clés : régression ridge, régression elasticnet, package glmnet, package tensorflow, package keras, ridge path, elasticnet path, coefficient de pénalité, validation croisée
Didacticiel : Ridge et elasticnet sous R
Données et programme : Adult dataset
Références :
Rakotomalala R., "Régression régularisée - Ridge, Lasso, Elasticnet", Mai 2018.
vendredi 18 mai 2018
Régression Lasso sous Python
Ce tutoriel fait suite au support de cours consacré à la régression régularisée. Nous travaillons sous Python avec le package « scikit-learn ».
Au-delà de la simple mise en oeuvre de la Régression Lasso, nous effectuons une comparaison avec la régression linéaire multiple usuelle telle qu’elle est proposée dans la librairie « StatsModels » pour montrer son intérêt. Nous verrons entres autres ses apports en termes de sélection de variables et d’optimisation des performances prédictives.
L’exemple est à vocation pédagogique, il s’agit avant tout de décortiquer les mécanismes de l’approche. J’ai par conséquent fait le choix d’utiliser une base de taille réduite (p = 16 variables explicatives) pour que les graphiques soient lisibles (le « Lasso path » par exemple). Dans ce contexte, les propriétés de régularisation de la Régression Lasso ne se démarquent pas vraiment.
Mots-clés : régression lasso, package scikit-learn, package statsmodels, lasso path, coefficient de pénalité, validation croisée
Didacticiel : Lasso Python
Données et programme : Baseball dataset
Références :
Rakotomalala R., "Régression régularisée - Ridge, Lasso, Elasticnet", Mai 2018.
Au-delà de la simple mise en oeuvre de la Régression Lasso, nous effectuons une comparaison avec la régression linéaire multiple usuelle telle qu’elle est proposée dans la librairie « StatsModels » pour montrer son intérêt. Nous verrons entres autres ses apports en termes de sélection de variables et d’optimisation des performances prédictives.
L’exemple est à vocation pédagogique, il s’agit avant tout de décortiquer les mécanismes de l’approche. J’ai par conséquent fait le choix d’utiliser une base de taille réduite (p = 16 variables explicatives) pour que les graphiques soient lisibles (le « Lasso path » par exemple). Dans ce contexte, les propriétés de régularisation de la Régression Lasso ne se démarquent pas vraiment.
Mots-clés : régression lasso, package scikit-learn, package statsmodels, lasso path, coefficient de pénalité, validation croisée
Didacticiel : Lasso Python
Données et programme : Baseball dataset
Références :
Rakotomalala R., "Régression régularisée - Ridge, Lasso, Elasticnet", Mai 2018.
vendredi 11 mai 2018
Ridge - Lasso - Elasticnet
La régression est la méthode la plus populaire auprès des data scientists (KDnuggets Polls, « Top 10 Data Science, Machine Learning Methods Used in 2017 », Décembre 2017). Elle existe depuis la nuit des temps (j’exagère un peu) et fait référence. Elle est de ces approches que l’on doit systématiquement essayer lorsqu’il s’agit de mettre en concurrence plusieurs algorithmes dans un problème d’analyse prédictive.
La régression doit faire face à de nouveaux enjeux ces dernières années, avec notamment la profusion des données à très forte dimensionnalité lors du traitement des données non-structurées. Un grand nombre de descripteurs sont automatiquement générés avec pour caractéristiques le bruit et la colinéarité. Les approches et implémentations classiques de la régression souffrent de ces situations. La régularisation devient une nécessité vitale pour éviter les phénomènes de surapprentissage.
Dans ce support de cours, nous présentons les approches Ridge, Lasso et Elasticnet dans le cadre de la régression linéaire multiple. Nous les étendons par la suite à la régression logistique. Les exemples utilisant les packages spécialisés pour R et Python permet de comprendre concrètement le comportement de ces algorithmes de machine learning.
La régression doit faire face à de nouveaux enjeux ces dernières années, avec notamment la profusion des données à très forte dimensionnalité lors du traitement des données non-structurées. Un grand nombre de descripteurs sont automatiquement générés avec pour caractéristiques le bruit et la colinéarité. Les approches et implémentations classiques de la régression souffrent de ces situations. La régularisation devient une nécessité vitale pour éviter les phénomènes de surapprentissage.
Dans ce support de cours, nous présentons les approches Ridge, Lasso et Elasticnet dans le cadre de la régression linéaire multiple. Nous les étendons par la suite à la régression logistique. Les exemples utilisant les packages spécialisés pour R et Python permet de comprendre concrètement le comportement de ces algorithmes de machine learning.
Mots-clés : diapos, régression régularisée, régression pénalisée, ridge, lasso, elasticnet, descente de gradient, régression linéaire multiple, régression logistique, packages R, packages python, glmnet, lars, mass, scikit-learn, tensorflow, keras
Support de cours : Régression régularisée
Références :
Hastie T., Tibshirani R., Friedman J., "Elements of statistical learning", Springer, corrected 12th, January 2017.
PennStat Eberly College of Science, "STAT 897D - Applied Data Mining and Statistical Learning".
mardi 1 mai 2018
Descente de gradient stochastique sous Python
Ce tutoriel fait suite au support de cours consacré à l’application de la méthode du gradient en apprentissage supervisé. Nous travaillons sous Python. Un document similaire a été écrit pour le logiciel R dans le cadre de la régression linéaire multiple.
Nous travaillons sur un problème de classement cette-fois. Nous souhaitons estimer les paramètres de la régression logistique à partir d’un ensemble de données étiquetées. Nous utilisons le package « scikit-learn » particulièrement populaire auprès des aficionados de Python . Nous étudierons l’influence du paramétrage sur la rapidité de la convergence de l’algorithme d’apprentissage et, de manière plus générale, sur la qualité du modèle obtenu. Nous en profiterons pour détailler une petite curiosité, parce que peu mise en avant dans les supports, que constitue la construction de la courbe ROC (Receiver Operating Characteristic) en validation croisée.
Mots-clés : descente de gradient stochastique, package scikit-learn, sklearn, régression logistique, python
Didacticiel : Descente de gradient stochastique
Données et programmes : sonar dataset
Références :
Rakotomalala R., "Descente de gradient - Diapos", avril 2018.
Tutoriel Tanagra, "Descente de gradient sous R", avril 2018.
Nous travaillons sur un problème de classement cette-fois. Nous souhaitons estimer les paramètres de la régression logistique à partir d’un ensemble de données étiquetées. Nous utilisons le package « scikit-learn » particulièrement populaire auprès des aficionados de Python . Nous étudierons l’influence du paramétrage sur la rapidité de la convergence de l’algorithme d’apprentissage et, de manière plus générale, sur la qualité du modèle obtenu. Nous en profiterons pour détailler une petite curiosité, parce que peu mise en avant dans les supports, que constitue la construction de la courbe ROC (Receiver Operating Characteristic) en validation croisée.
Mots-clés : descente de gradient stochastique, package scikit-learn, sklearn, régression logistique, python
Didacticiel : Descente de gradient stochastique
Données et programmes : sonar dataset
Références :
Rakotomalala R., "Descente de gradient - Diapos", avril 2018.
Tutoriel Tanagra, "Descente de gradient sous R", avril 2018.
jeudi 26 avril 2018
Descente de gradient sous R
Ce tutoriel fait suite au support de cours consacré à l’application de la méthode du gradient en apprentissage supervisé. Nous travaillons sous R. Un document consacré à Python viendra par la suite.
Nous nous plaçons dans le cadre de la régression linéaire multiple. Dans un premier temps, nous traiterons un jeu de données réduit qui nous permettra d’étudier en détail le comportement des algorithmes de descente de gradient, stochastique ou non. L’idée est de comparer les coefficients estimés et les valeurs de la fonction de perte obtenues à l’issue du processus d’apprentissage. Dans un second temps, nous traiterons un fichier réaliste de classement de protéines où le nombre de variables est élevé, son ratio par rapport au nombre d’observations est largement supérieur à 1. Dans ce cas, l’implémentation usuelle de la régression sous R, lm() du package « stats », même si elle est solide, n’est pas opérationnelle. Seules les approches basées sur la descente de gradient permettent de produire un résultat exploitable.
Nous utiliserons les packages ‘gradDescent’ et ‘tensorflow / keras’. Ce dernier tandem a été présenté plus en détail dans un précédent document (Avril 2018). Il faut s’y référer notamment pour la partie installation qui n’est pas triviale.
Mots-clés : descente de gradient, algorithme du gradient, gradient stochastique, logiciel R, package gradDescent, packages tensorflow, keras, régression, régression linéaire multiple, classement de protéines
Didacticiel : Descente de gradient sous R
Données et programmes : artificial + protein
Références :
R. Rakotomalala, "Descente de gradient - Diapos", avril 2018.
Tutoriel Tanagra, "Deep learning - Tensorflow et Keras sous R", avril 2018.
Tutoriel Tanagra, "Descente de gradient stochastique sous Python", mai 2018.
Nous nous plaçons dans le cadre de la régression linéaire multiple. Dans un premier temps, nous traiterons un jeu de données réduit qui nous permettra d’étudier en détail le comportement des algorithmes de descente de gradient, stochastique ou non. L’idée est de comparer les coefficients estimés et les valeurs de la fonction de perte obtenues à l’issue du processus d’apprentissage. Dans un second temps, nous traiterons un fichier réaliste de classement de protéines où le nombre de variables est élevé, son ratio par rapport au nombre d’observations est largement supérieur à 1. Dans ce cas, l’implémentation usuelle de la régression sous R, lm() du package « stats », même si elle est solide, n’est pas opérationnelle. Seules les approches basées sur la descente de gradient permettent de produire un résultat exploitable.
Nous utiliserons les packages ‘gradDescent’ et ‘tensorflow / keras’. Ce dernier tandem a été présenté plus en détail dans un précédent document (Avril 2018). Il faut s’y référer notamment pour la partie installation qui n’est pas triviale.
Mots-clés : descente de gradient, algorithme du gradient, gradient stochastique, logiciel R, package gradDescent, packages tensorflow, keras, régression, régression linéaire multiple, classement de protéines
Didacticiel : Descente de gradient sous R
Données et programmes : artificial + protein
Références :
R. Rakotomalala, "Descente de gradient - Diapos", avril 2018.
Tutoriel Tanagra, "Deep learning - Tensorflow et Keras sous R", avril 2018.
Tutoriel Tanagra, "Descente de gradient stochastique sous Python", mai 2018.
vendredi 20 avril 2018
Descente de gradient - Diapos
Application du principe de la descente de gradient à l’apprentissage supervisé. Exemples avec la régression linéaire multiple et la régression logistique.
La volumétrie est un problème récurrent du machine learning. La majorité des algorithmes reposent sur la formulation d’une optimisation. Il devient très difficile de les mettre en œuvre sur les bases actuelles qui sont parfois aussi larges (si ce n’est plus) que longues. L’algorithme du gradient connaît un regain d’intérêt certain dans ce contexte. En effet, d’une part, il permet de revisiter les méthodes statistiques existantes comme la régression, d’autre part, il devient incontournable dans les méthodes très populaires aujourd’hui telles que le deep learning.
Ce support de cours présente le principe descente de gradient. Il montre concrètement son implémentation dans le cadre de la régression linéaire multiple et la régression logistique binaire et multinomiale. Quelques packages pour Python (scikit-learn, tensorflow / keras) et R (gradDescent) sont mis en avant.
Mots-clés : gradient descent, stochastic gradient descent, descente de gradient stochastique, régression linéaire multiple, régression logistique, python, logiciel R, tensorflow, keras, scikit-learn, gradDescent, perceptron
Support de cours : Descente de gradient
Références :
Wikipedia, "Gradient descent".
Wikipedia, "Stochastic gradient descent".
La volumétrie est un problème récurrent du machine learning. La majorité des algorithmes reposent sur la formulation d’une optimisation. Il devient très difficile de les mettre en œuvre sur les bases actuelles qui sont parfois aussi larges (si ce n’est plus) que longues. L’algorithme du gradient connaît un regain d’intérêt certain dans ce contexte. En effet, d’une part, il permet de revisiter les méthodes statistiques existantes comme la régression, d’autre part, il devient incontournable dans les méthodes très populaires aujourd’hui telles que le deep learning.
Ce support de cours présente le principe descente de gradient. Il montre concrètement son implémentation dans le cadre de la régression linéaire multiple et la régression logistique binaire et multinomiale. Quelques packages pour Python (scikit-learn, tensorflow / keras) et R (gradDescent) sont mis en avant.
Mots-clés : gradient descent, stochastic gradient descent, descente de gradient stochastique, régression linéaire multiple, régression logistique, python, logiciel R, tensorflow, keras, scikit-learn, gradDescent, perceptron
Support de cours : Descente de gradient
Références :
Wikipedia, "Gradient descent".
Wikipedia, "Stochastic gradient descent".
vendredi 13 avril 2018
Deep Learning - Tensorflow et Keras sous R
Python et R sont les deux mamelles généreuses de la fertilité intellectuelle du data scientist. Parfois elles sont interchangeables, parfois elles se complètent. En tous les cas, elles nourrissent la pratique de la data science. Et, finalement, le choix entre ces fontaines de jouvence est avant tout affaire de goûts personnels, de circonstances, d’environnements de travail, de disponibilité des packages…
Ce tutoriel fait suite à un document récent consacré au deep learning via les librairies Tensorflow et Keras sous Python. Nous en reprenons les étapes point par point, mais sous R cette fois-ci. Nous verrons que la transposition est particulièrement simple.
Mots-clés : deep learning, tensorflow, keras, perceptron simple, perceptron multicouche, logiciel R
Didacticiel : Tensorflow et Keras sous R
Données et programmes : 2D
Références :
Tutoriel Tanagra, "Deep Learning avec Tensorflow et Keras (Python)", avril 2018.
Ce tutoriel fait suite à un document récent consacré au deep learning via les librairies Tensorflow et Keras sous Python. Nous en reprenons les étapes point par point, mais sous R cette fois-ci. Nous verrons que la transposition est particulièrement simple.
Mots-clés : deep learning, tensorflow, keras, perceptron simple, perceptron multicouche, logiciel R
Didacticiel : Tensorflow et Keras sous R
Données et programmes : 2D
Références :
Tutoriel Tanagra, "Deep Learning avec Tensorflow et Keras (Python)", avril 2018.
mercredi 11 avril 2018
Deep Learning avec Tensorflow et Keras (Python)
Tensorflow est une bibliothèque open-source développée par l’équipe Google Brain qui l’utilisait initialement en interne. Elle implémente des méthodes d’apprentissage automatique basées sur le principe des réseaux de neurones profonds (deep learning). Une API Python est disponible. Nous pouvons l’exploiter directement dans un programme rédigé en Python. C’est faisable, il existe des tutoriels et des ouvrages à ce sujet. Pourtant, j’ai préféré passer par Keras parce que le formalisme imposé par Tensorflow est déroutant au possible pour un néophyte. Découvrir de nouveaux algorithmes devient vite rédhibitoire si on a du mal à se dépatouiller avec un outil que nous sommes censés utiliser pour les mettre en application.
Keras est une librairie Python qui encapsule l’accès aux fonctions proposées par plusieurs librairies de machine learning, en particulier Tensorflow. De fait, Keras n’implémente pas nativement les méthodes. Elle sert d’interface avec Tensorflow simplement. Mais pourquoi alors s’enquiquiner avec une surcouche supplémentaire direz-vous ? Parce qu’elle nous facilite grandement la vie en proposant des fonctions et procédures relativement simples à mettre en œuvre. Un apprenant qui a déjà assimilé les démarches types du machine learning, qui a pu par ailleurs utiliser des librairies qui font référence telles que scikit-learn, ne sera pas dépaysé lorsqu’il aura à travailler avec Keras. L’accès aux fonctionnalités de Tensorflow devenant transparentes, il pourra se focaliser sur la compréhension des méthodes.
Ce tutoriel a pour objectif la prise en main des outils. Pour aller à l’essentiel, nous implémenterons des perceptrons simples et multicouches dans des problèmes d’analyse prédictive. Ayant déjà nos repères concernant ces méthodes, nous pourrons nous consacrer pleinement à l’assimilation du mode de fonctionnement du tandem Tensorflow - Keras. Les supports de cours consacrés aux méthodes de Deep Learning suivront.
Mots-clés : deep learning, package keras, package tensorflow, python, anaconda, perceptron simple, perceptron multicouche
Didacticiel : Tensorflow Keras sous Python
Données et programmes : 2D et wine
Références :
Tutoriel Tanagra, "Paramétrer le perceptron multicouche", avril 2013.
Tutoriel Tanagra, "Deep Learning - Tensorflow et Keras sous R", avril 2018.
Keras est une librairie Python qui encapsule l’accès aux fonctions proposées par plusieurs librairies de machine learning, en particulier Tensorflow. De fait, Keras n’implémente pas nativement les méthodes. Elle sert d’interface avec Tensorflow simplement. Mais pourquoi alors s’enquiquiner avec une surcouche supplémentaire direz-vous ? Parce qu’elle nous facilite grandement la vie en proposant des fonctions et procédures relativement simples à mettre en œuvre. Un apprenant qui a déjà assimilé les démarches types du machine learning, qui a pu par ailleurs utiliser des librairies qui font référence telles que scikit-learn, ne sera pas dépaysé lorsqu’il aura à travailler avec Keras. L’accès aux fonctionnalités de Tensorflow devenant transparentes, il pourra se focaliser sur la compréhension des méthodes.
Ce tutoriel a pour objectif la prise en main des outils. Pour aller à l’essentiel, nous implémenterons des perceptrons simples et multicouches dans des problèmes d’analyse prédictive. Ayant déjà nos repères concernant ces méthodes, nous pourrons nous consacrer pleinement à l’assimilation du mode de fonctionnement du tandem Tensorflow - Keras. Les supports de cours consacrés aux méthodes de Deep Learning suivront.
Mots-clés : deep learning, package keras, package tensorflow, python, anaconda, perceptron simple, perceptron multicouche
Didacticiel : Tensorflow Keras sous Python
Données et programmes : 2D et wine
Références :
Tutoriel Tanagra, "Paramétrer le perceptron multicouche", avril 2013.
Tutoriel Tanagra, "Deep Learning - Tensorflow et Keras sous R", avril 2018.
jeudi 5 avril 2018
Machine learning avec caret
La profusion des packages est à la fois une force et une faiblesse de R. Une force parce que cette richesse permet de couvrir une très large fraction de la pratique des statistiques et du machine learning. Aujourd’hui, face à tout type de problème, la première question que l’on se pose est : “est-ce qu’il n’y a pas déjà un package qui permet de le faire simplement ?”. Mais c’est aussi une faiblesse parce qu’il y a une très forte hétérogénéité des pratiques et modes opératoires des packages. Et la documentation n’est pas toujours explicite malheureusement. Il m’arrive d’aller voir dans le code même pour comprendre réellement ce qui est implémenté. L’affaire se corse d’autant plus que nous devons souvent combiner (jongler entre) plusieurs packages pour mettre en place une analyse complète.
Le package “caret” (Classification And REgression Training) est une librairie pour R. Il couvre une large fraction de la pratique de l’analyse prédictive (classement et régression). Un peu à la manière de “scikit-learn” pour Python, il intègre dans un ensemble cohérent les étapes clés de la modélisation : préparation des données, sélection, apprentissage, évaluation. La standardisation des prototypes des fonctions d’apprentissage et de prédiction notamment permet de simplifier notre code, facilitant les tâches d’optimisation et de comparaison des modèles.
Dans ce tutoriel, à partir d’un exemple d’identification de “spams”, nous montrons quelques facettes du package “caret”.
Mots-clés : analyse prédictive, classement, régression, régression logistique, svm, support vector machine, optimisation des paramètres, techniques de rééchantillonnage, validation croisée, courbe lift, courbe roc
Didacticiel : Machine learning avec "caret"
Données : spam_caret.txt
Référénces :
Max Kuhn, "The caret Package", 2017.
Le package “caret” (Classification And REgression Training) est une librairie pour R. Il couvre une large fraction de la pratique de l’analyse prédictive (classement et régression). Un peu à la manière de “scikit-learn” pour Python, il intègre dans un ensemble cohérent les étapes clés de la modélisation : préparation des données, sélection, apprentissage, évaluation. La standardisation des prototypes des fonctions d’apprentissage et de prédiction notamment permet de simplifier notre code, facilitant les tâches d’optimisation et de comparaison des modèles.
Dans ce tutoriel, à partir d’un exemple d’identification de “spams”, nous montrons quelques facettes du package “caret”.
Mots-clés : analyse prédictive, classement, régression, régression logistique, svm, support vector machine, optimisation des paramètres, techniques de rééchantillonnage, validation croisée, courbe lift, courbe roc
Didacticiel : Machine learning avec "caret"
Données : spam_caret.txt
Référénces :
Max Kuhn, "The caret Package", 2017.
jeudi 29 mars 2018
ACP sous Excel avec Xnumbers
Tout le monde l’a bien compris, le tableur est pour moi avant tout un outil pédagogique pour l’enseignement de la statistique et du data mining. Les étudiants ne peuvent pas entrer des commandes ou cliquer frénétiquement au petit bonheur la chance. Ils doivent regarder de près les formules pour pouvoir les comprendre et les reproduire. Il n’y a pas mieux pour les amener à décortiquer les différentes étapes du calcul quelle que soit la méthode étudiée.
Nous avions analysé la Régression Linéaire Multiple sous Excel récemment (Mars 2018). Dans ce tutoriel, nous explorons la mécanique d’une autre méthode phare de la data science (voir Top Data Science and Machine Learning Used in 2017) : l’analyse en composantes principales (ACP). J’en profiterai pour présenter Xnumbers, une librairie particulièrement performante pour le calcul scientifique sous Excel. Elle nous sera utile en particulier pour la factorisation des matrices à l’aide de la décomposition en valeurs singulières.
Nous avions analysé la Régression Linéaire Multiple sous Excel récemment (Mars 2018). Dans ce tutoriel, nous explorons la mécanique d’une autre méthode phare de la data science (voir Top Data Science and Machine Learning Used in 2017) : l’analyse en composantes principales (ACP). J’en profiterai pour présenter Xnumbers, une librairie particulièrement performante pour le calcul scientifique sous Excel. Elle nous sera utile en particulier pour la factorisation des matrices à l’aide de la décomposition en valeurs singulières.
Mots-clés : analyse en composantes principales, acp, tableur excel, xnumbers
Didacticiel : ACP sous Excel
Classeur Excel : acp autos.xlsx
Références :
R. Rakotomalala, "Analyse en composantes principales - Diapos", Juillet 2013.
mardi 27 mars 2018
Autoformation avec swirl
L’autoformation est un des leviers essentiels de notre progression. J'essaie de contribuer moi-même à mon échelle à travers les supports de cours et les tutoriels. Une voie alternative est le tutoriel où on guide explicitement l'apprenant avec des systèmes de questions-réponses et des exercices contrôlés.
Le package swirl pour R fait partie de cette seconde catégorie. Une ancienne du Master SISE qui assure des formations sous R me l'a indiqué. Je la remercie pour cela. Malgré le temps que je passe sur le web à scruter ce qui se fait, beaucoup de choses m'échappent. Elle m'indiquait qu’elle l’utilisait avec succès pour ses séances de cours. Bien évidemment que je me suis rué dessus pour voir un peu ce qu'il en était, et le parti que je pourrais en tirer pour mes propres enseignements.
Dans ce tutoriel, nous essaierons de faire le tour de l'outil pédagogique en montrant son mode de fonctionnement sur un exemple de séance consacrée à la régression linéaire multiple. Nous en profiterons pour regarder un peu sous le capot et voir les éléments constitutifs des cours.
Mots-clés : autoapprentissage, autoformation, package R, logiciel R, régression linéaire multiple
Didacticiel : Apprendre R, sous R
Références :
Swirl : Learn R, in R -- http://swirlstats.com/
Le package swirl pour R fait partie de cette seconde catégorie. Une ancienne du Master SISE qui assure des formations sous R me l'a indiqué. Je la remercie pour cela. Malgré le temps que je passe sur le web à scruter ce qui se fait, beaucoup de choses m'échappent. Elle m'indiquait qu’elle l’utilisait avec succès pour ses séances de cours. Bien évidemment que je me suis rué dessus pour voir un peu ce qu'il en était, et le parti que je pourrais en tirer pour mes propres enseignements.
Dans ce tutoriel, nous essaierons de faire le tour de l'outil pédagogique en montrant son mode de fonctionnement sur un exemple de séance consacrée à la régression linéaire multiple. Nous en profiterons pour regarder un peu sous le capot et voir les éléments constitutifs des cours.
Mots-clés : autoapprentissage, autoformation, package R, logiciel R, régression linéaire multiple
Didacticiel : Apprendre R, sous R
Références :
Swirl : Learn R, in R -- http://swirlstats.com/
vendredi 23 mars 2018
Requêtes avec jointures sous R
Dans ma pratique usuelle, lorsque je dois traiter des bases multi-tables dans un processus de modélisation, j’effectue une partie du pre-processing avec des SGBD (système de gestion de base de données). Avec le langage SQL (structured query language), on y est à l’aise pour effectuer des requêtes mettant en œuvre des jointures complexes entre plusieurs sources. Au final, une table unique propice à l’analyse est produite, que j’importe ensuite dans le logiciel d’analyse statistique, que ce soit R ou Python.
Cette approche n’est pas toujours adaptée lorsque les sources initiales sont susceptibles de mises à jour fréquentes. Une modification des données nécessiterait la ré-exécution des requêtes en amont avant de pouvoir relancer le processus de modélisation. Dans ce cas, il est plus judicieux d’intégrer le code de la phase de requêtage dans le programme réalisant le traitement statistique.
Dans ce tutoriel, nous étudions les différentes solutions à notre disposition sous R pour effectuer des requêtes avec jointures. Elles ont toutes permis de répondre au cahier des charges, avec plus ou moins de facilité. Finalement, il nous appartient de choisir celle qui est la plus adaptée par rapport à notre cahier des charges.
Mots-clés : requêtes, jointures, SQL, package dplyr, fusion, tables, package sqldf
Didacticiel : Requêtes avec jointures
Données : Movies Dataset
Références :
Package "sqldf" ; package "dplyr".
Cette approche n’est pas toujours adaptée lorsque les sources initiales sont susceptibles de mises à jour fréquentes. Une modification des données nécessiterait la ré-exécution des requêtes en amont avant de pouvoir relancer le processus de modélisation. Dans ce cas, il est plus judicieux d’intégrer le code de la phase de requêtage dans le programme réalisant le traitement statistique.
Dans ce tutoriel, nous étudions les différentes solutions à notre disposition sous R pour effectuer des requêtes avec jointures. Elles ont toutes permis de répondre au cahier des charges, avec plus ou moins de facilité. Finalement, il nous appartient de choisir celle qui est la plus adaptée par rapport à notre cahier des charges.
Mots-clés : requêtes, jointures, SQL, package dplyr, fusion, tables, package sqldf
Didacticiel : Requêtes avec jointures
Données : Movies Dataset
Références :
Package "sqldf" ; package "dplyr".
vendredi 16 mars 2018
Régression linéaire sous Excel
Dans ce tutoriel, nous reprenons à partir d’un exemple traité sous Excel les principaux concepts présentés dans les documents accessibles sur ma page de cours d’Econométrie. Deux ouvrages en particulier seront mis à contribution (voir Références du document). Les principales formules seront explicitées pour chaque calcul. Elles seront mises en relation avec les opérations sous Excel. Puisque nous traitons de la régression linéaire multiple, nous ferons un usage intensif des fonctions matricielles du tableur.
Mots-clés : régression linéaire simple et multiple, excel, droitereg, fonctions matricielles
Didacticiel : Régression sous Excel
Classeur Excel : Données "cigarettes"
Références :
Cours Économétrie - Modèles linéaires
Tutoriel Tanagra, "Classeur Économétrie", avril 2015.
Mots-clés : régression linéaire simple et multiple, excel, droitereg, fonctions matricielles
Didacticiel : Régression sous Excel
Classeur Excel : Données "cigarettes"
Références :
Cours Économétrie - Modèles linéaires
Tutoriel Tanagra, "Classeur Économétrie", avril 2015.
mercredi 14 mars 2018
Panne partielle du serveur Eric
Depuis le 12 mars 2018 à 15h11, le serveur eric.univ-lyon2.fr utilise un certificat de sécurité invalide. Les accès en https nécessitent l'ajout d'une exception de sécurité. Il n'y a aucune crainte à avoir.
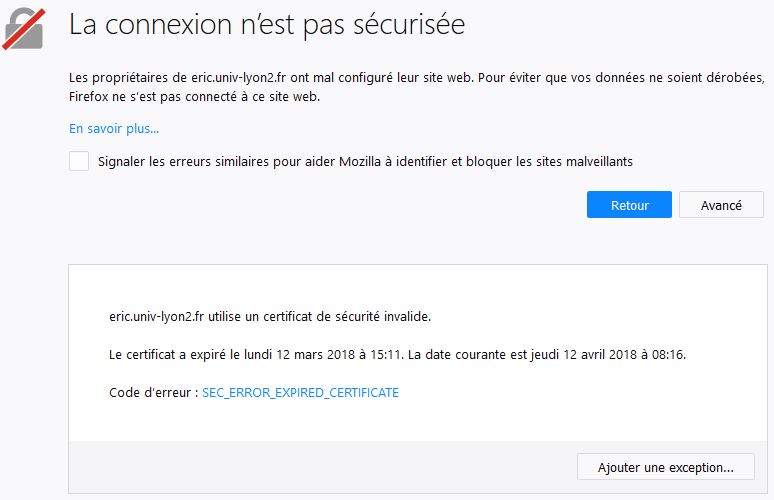
Je ne sais pas quand ce problème sera résolu.
Pour l'heure, la solution la plus simple consiste à modifier manuellement les adresses https en http.
Je suis désolé de ce désagrément.
Ricco.
Je ne sais pas quand ce problème sera résolu.
Pour l'heure, la solution la plus simple consiste à modifier manuellement les adresses https en http.
Je suis désolé de ce désagrément.
Ricco.
mercredi 21 février 2018
Stratégies d'échantillonnage pour la modélisation
Ce tutoriel fait suite au support de cours consacré aux algorithmes d'échantillonnage. Nous nous y intéressions en particulier aux stratégies d'échantillonnage pour la modélisation prédictive.
Dans ce document, nous étudions expérimentalement le comportement des deux stratégies décrites dans le support. L'approche "random sampling" consiste à démarrer à partir d'une taille d'échantillon définie a priori, puis de l'augmenter graduellement tout en surveillant les performances en test (taux d'erreur). La méthode "windowing" procède du même principe mais cherche à sélectionner judicieusement les observations additionnelles à chaque étape pour améliorer la convergence.
Nos algorithmes et bases de référence seront respectivement l'analyse discriminante linéaire et les données WAVEFORM bien connus des data scientists. L'étude a été menée sous R. Mais le portage du code dans d'autres langages comme Python ne pose aucun problème conceptuel.
Mots-clés : échantillonnage, random sampling, windowing, apprentissage supervisé
Document : Stratégies d'échantillonnage pour la modélisation
Données : waveform dataset
Références :
Tutoriel Tanagra, "Algorithmes d'échantillonnage", février 2018.
Dans ce document, nous étudions expérimentalement le comportement des deux stratégies décrites dans le support. L'approche "random sampling" consiste à démarrer à partir d'une taille d'échantillon définie a priori, puis de l'augmenter graduellement tout en surveillant les performances en test (taux d'erreur). La méthode "windowing" procède du même principe mais cherche à sélectionner judicieusement les observations additionnelles à chaque étape pour améliorer la convergence.
Nos algorithmes et bases de référence seront respectivement l'analyse discriminante linéaire et les données WAVEFORM bien connus des data scientists. L'étude a été menée sous R. Mais le portage du code dans d'autres langages comme Python ne pose aucun problème conceptuel.
Mots-clés : échantillonnage, random sampling, windowing, apprentissage supervisé
Document : Stratégies d'échantillonnage pour la modélisation
Données : waveform dataset
Références :
Tutoriel Tanagra, "Algorithmes d'échantillonnage", février 2018.
mercredi 14 février 2018
Algorithmes d'échantillonnage
La volumétrie est un des enjeux clés du big data analytics. Des technologies spécifiques sont développées à cet effet. Mais d’autres stratégies existent. L’échantillonnage en est une. Dans le cadre de l’apprentissage supervisé par exemple, l’idée serait de modéliser à partir d’une fraction des données, choisies plus ou moins judicieusement, tout en s’assurant un niveau de performances équivalent au modèle qui aurait été élaboré à partir de la totalité des observations.
Mais avant d’en arriver à ce stade, il faut déjà pouvoir extraire l’échantillon à partir des données initiales. Ce support présente différents algorithmes permettant de traiter un fichier texte CSV (comma-separated value) de grande taille en accès séquentiel qu’il n’est pas possible de charger entièrement en mémoire vive. Deux grandes variantes sont explicitées : la première, plus simple, suppose connue la taille de la base initiale ; la seconde, nécessitant le chargement en mémoire de l’échantillon ou l’utilisation d’une structure intermédiaire autorisant un accès indexé, traite des fichiers où le nombre de lignes n’est pas connu à l’avance.
Des exemples de codes sources en R et Python permettent d’illustrer concrètement les solutions.
Mots-clés : échantillon, méthode de sélection rejet, reservoir sampling, fichier CSV, fichier texte avec séparateur tabulation, modélisation prédictive, logiciel R, python
Support de cours : Algorithmes d'échantillonnage
Références :
Wikipedia, "Reservoir sampling".
Mais avant d’en arriver à ce stade, il faut déjà pouvoir extraire l’échantillon à partir des données initiales. Ce support présente différents algorithmes permettant de traiter un fichier texte CSV (comma-separated value) de grande taille en accès séquentiel qu’il n’est pas possible de charger entièrement en mémoire vive. Deux grandes variantes sont explicitées : la première, plus simple, suppose connue la taille de la base initiale ; la seconde, nécessitant le chargement en mémoire de l’échantillon ou l’utilisation d’une structure intermédiaire autorisant un accès indexé, traite des fichiers où le nombre de lignes n’est pas connu à l’avance.
Des exemples de codes sources en R et Python permettent d’illustrer concrètement les solutions.
Mots-clés : échantillon, méthode de sélection rejet, reservoir sampling, fichier CSV, fichier texte avec séparateur tabulation, modélisation prédictive, logiciel R, python
Support de cours : Algorithmes d'échantillonnage
Références :
Wikipedia, "Reservoir sampling".
samedi 3 février 2018
Master SISE - Remise à niveau - Python Statistique
Le temps des recrutements pour le Master SISE va commencer bientôt. Le programme de remise à niveau pour les candidatures externes acceptées est étoffé par un chapitre consacré à Python.
L’objectif est de familiariser l’étudiant avec la manipulation des données, la réalisation des calculs statistiques simples (statistiques descriptives) ou un peu plus poussées (classification automatique, clustering). Ces exercices visent aussi à introduire quelques packages Python fondamentaux, indispensables au data scientist (pandas, numpy, scipy, matplotlib).
A la sortie, l’étudiant, j’espère en tous les cas, sera fin prêt pour suivre les enseignements où nous, mes collègues et moi-même, utilisons intensivement Python, souvent en tandem avec R (j'utilise indifféremment l'un ou l'autre pour mes cours [data mining, text mining, web mining], j'avertis les étudiants un peu avant la séance simplement pour qu'ils puissent se préparer).
Document principal : Python Statistique
Outils : Anaconda Python
Exercice 1 : Pandas, manipulation des données (Produits)
Exercice 2 : Pandas, quelques traitements (Census)
Exercice 3 : Scipy, statistiques simples et avancées (Iris)
L’objectif est de familiariser l’étudiant avec la manipulation des données, la réalisation des calculs statistiques simples (statistiques descriptives) ou un peu plus poussées (classification automatique, clustering). Ces exercices visent aussi à introduire quelques packages Python fondamentaux, indispensables au data scientist (pandas, numpy, scipy, matplotlib).
A la sortie, l’étudiant, j’espère en tous les cas, sera fin prêt pour suivre les enseignements où nous, mes collègues et moi-même, utilisons intensivement Python, souvent en tandem avec R (j'utilise indifféremment l'un ou l'autre pour mes cours [data mining, text mining, web mining], j'avertis les étudiants un peu avant la séance simplement pour qu'ils puissent se préparer).
Document principal : Python Statistique
Outils : Anaconda Python
Exercice 1 : Pandas, manipulation des données (Produits)
Exercice 2 : Pandas, quelques traitements (Census)
Exercice 3 : Scipy, statistiques simples et avancées (Iris)
jeudi 18 janvier 2018
R ou Python, il faut choisir ?
Une bonne manière de gâcher un repas entre informaticiens est de lancer un débat sur le meilleur langage de programmation (vécu). J’imagine qu’on aura sûrement la même chose si l’on essaie de comparer R et Python dans un dîner entre data scientist (je préfère ne pas essayer).
Mais pourquoi les opposer finalement ? Ne peut-on pas avoir fromage et dessert au même repas (pour poursuivre dans la parabole gastronomique) ? On peut former les étudiants à ces deux outils simultanément. Je les utilise moi-même de manière indifférenciée dans mes travaux dirigés en Master SISE. Et on s’en sort plutôt bien (je trouve).
C’est le discours que je vais tenir lors de la présentation au Meetup de l’association Lyon Data Science auquel je participerai ce vendredi 19 janvier 2018. En m’appuyant sur ma propre expérience d’enseignant-chercheur et de concepteur de logiciels gratuits à visée pédagogique, je vais essayer de retracer le cheminement intellectuel qui m’a amené à utiliser intensivement à la fois R et Python dans mes enseignements actuels.
Voici le résumé et le support de la présentation.
Titre : « Place de R et Python dans les formations en data science »
Résumé : La science des données n’échappe pas à la vague des logiciels libres. Depuis plusieurs années, les deux outils les plus populaires auprès des data scientists sont R et Python selon le sondage annuel du site KDnuggets (Mai 2017). Certes, les licences présentent des subtilités un peu difficiles à suivre parfois, mais elles respectent deux caractéristiques fondamentales de mon point de vue : nous avons accès au code source, nous garantissant un certain contrôle sur les calculs et opérations réellement effectuées ; ils sont accessibles et exploitables gratuitement, quels que soient les contextes d’utilisation. De fait, l’adoption de R et Python dans les formations en data science semble évidente. Pourtant, il faut être prudent, ne serait-ce que par principe. Former les étudiants à un outil n’équivaut pas à utiliser un ou des outils pour former les étudiants. Leur usage doit s’inscrire dans une démarche pédagogique cohérente qui peut s’étendre sur plusieurs années. Il ne doit pas reposer sur des effets de modes ou des popularités qui peuvent être parfois éphémères.
Dans mon exposé, je m’appuierai sur ma propre expérience d’enseignant d’une part, de créateur de logiciels de data mining gratuits à vocation pédagogique (SIPINA, TANAGRA) d’autre part, pour essayer de cerner les attentes que l’on peut avoir vis-à-vis des outils dans les cours de statistique et de data science. L’élaboration de TANAGRA (2004) en particulier aura été l’occasion de mener une réflexion approfondie sur les caractéristiques clés que doivent présenter les logiciels pour l’enseignement. Je reviendrai rapidement dessus pour mieux rebondir sur la définition d’un cahier des charges actualisé où les compétences en programmation et les accès aux API tiennent une place importante. Dans ce contexte, que l’on pourrait qualifier de Big Data, R et Python se démarquent réellement et justifient pleinement l’investissement que l’on pourrait leur consacrer au sein des formations. D’autant plus que leur présence de plus en plus marquée dans les offres d’emploi qui nous concernent directement est une autre raison qui ne peut pas nous laisser insensible. Je m’appuierais sur une étude récente réalisée par un groupe d’étudiants du Master SISE pour essayer de cerner les mots clés importants qui caractérisent les annonces dans nos domaines en France. Python y occupe un espace assez singulier.
Plusieurs démonstrations mettant en oeuvre R et Python me permettront d'appuyer mon propos.
Support : R et Python dans les enseignements
Vidéo : Meetup à la Tour du Web
Mots-clés : data science, enseignement, formation, master data science, science de données, big data, big data analytics, logiciels libres, r, python
Mais pourquoi les opposer finalement ? Ne peut-on pas avoir fromage et dessert au même repas (pour poursuivre dans la parabole gastronomique) ? On peut former les étudiants à ces deux outils simultanément. Je les utilise moi-même de manière indifférenciée dans mes travaux dirigés en Master SISE. Et on s’en sort plutôt bien (je trouve).
C’est le discours que je vais tenir lors de la présentation au Meetup de l’association Lyon Data Science auquel je participerai ce vendredi 19 janvier 2018. En m’appuyant sur ma propre expérience d’enseignant-chercheur et de concepteur de logiciels gratuits à visée pédagogique, je vais essayer de retracer le cheminement intellectuel qui m’a amené à utiliser intensivement à la fois R et Python dans mes enseignements actuels.
Voici le résumé et le support de la présentation.
Titre : « Place de R et Python dans les formations en data science »
Résumé : La science des données n’échappe pas à la vague des logiciels libres. Depuis plusieurs années, les deux outils les plus populaires auprès des data scientists sont R et Python selon le sondage annuel du site KDnuggets (Mai 2017). Certes, les licences présentent des subtilités un peu difficiles à suivre parfois, mais elles respectent deux caractéristiques fondamentales de mon point de vue : nous avons accès au code source, nous garantissant un certain contrôle sur les calculs et opérations réellement effectuées ; ils sont accessibles et exploitables gratuitement, quels que soient les contextes d’utilisation. De fait, l’adoption de R et Python dans les formations en data science semble évidente. Pourtant, il faut être prudent, ne serait-ce que par principe. Former les étudiants à un outil n’équivaut pas à utiliser un ou des outils pour former les étudiants. Leur usage doit s’inscrire dans une démarche pédagogique cohérente qui peut s’étendre sur plusieurs années. Il ne doit pas reposer sur des effets de modes ou des popularités qui peuvent être parfois éphémères.
Dans mon exposé, je m’appuierai sur ma propre expérience d’enseignant d’une part, de créateur de logiciels de data mining gratuits à vocation pédagogique (SIPINA, TANAGRA) d’autre part, pour essayer de cerner les attentes que l’on peut avoir vis-à-vis des outils dans les cours de statistique et de data science. L’élaboration de TANAGRA (2004) en particulier aura été l’occasion de mener une réflexion approfondie sur les caractéristiques clés que doivent présenter les logiciels pour l’enseignement. Je reviendrai rapidement dessus pour mieux rebondir sur la définition d’un cahier des charges actualisé où les compétences en programmation et les accès aux API tiennent une place importante. Dans ce contexte, que l’on pourrait qualifier de Big Data, R et Python se démarquent réellement et justifient pleinement l’investissement que l’on pourrait leur consacrer au sein des formations. D’autant plus que leur présence de plus en plus marquée dans les offres d’emploi qui nous concernent directement est une autre raison qui ne peut pas nous laisser insensible. Je m’appuierais sur une étude récente réalisée par un groupe d’étudiants du Master SISE pour essayer de cerner les mots clés importants qui caractérisent les annonces dans nos domaines en France. Python y occupe un espace assez singulier.
Plusieurs démonstrations mettant en oeuvre R et Python me permettront d'appuyer mon propos.
Support : R et Python dans les enseignements
Vidéo : Meetup à la Tour du Web
Mots-clés : data science, enseignement, formation, master data science, science de données, big data, big data analytics, logiciels libres, r, python
samedi 6 janvier 2018
Ressources partagées - Apprentissage supervisé
Antoine Rolland, un collègue qui officie à l’IUT STID de l’Université Lyon 2, m’a demandé de contribuer à la revue "Statistique et Enseignement". J’ai accepté parce que c’est lui qui me l’a demandé. Aussi parce qu’il s’agit d’une revue librement consultable, gratuitement, sans aucune contrainte.
Antoine m’a proposé de faire un descriptif commenté d’un de mes supports de cours. Ca m’a un peu titillé l’esprit. Faire l’exégèse de son propre travail n’est jamais facile. J’ai eu un peu de mal à démarrer j’avoue, puis j’ai eu beaucoup de plaisir à le faire une fois lancé. Comme tout enseignant chercheur, je parle beaucoup durant un cours, sans y penser réellement de manière explicite en amont. J’aborde tout un tas de sujets en relation d’une part avec mon expérience ou même l’actualité, d’autre part avec le profil des étudiants que j’ai en face de moi. Heureusement d’ailleurs, sinon je ne vois pas très bien l’intérêt pour nous de faire des cours magistraux (CM), à ânonner béatement la même chose tous les ans en lisant les slides. Je pense même que l’interaction est la seule justification valable encore aujourd’hui de l’existence des CM. Autrement, il y a pléthore de supports sur le web, y compris des cours en vidéo très bien faits de collègues très compétents. Décalquer avec plus ou moins de bonheur ce que dit tout le monde n’a pas vraiment d’intérêt.
J’ai choisi de travailler sur mon support de cours dédié à l’Introduction de l’apprentissage supervisé. Il s’agit d’un CM crucial où j’essaie de faire appréhender aux étudiants les notions clés de l’analyse prédictive. Chaque slide est décrit de manière approfondie, avec les commentaires qui peuvent me venir à l’esprit, les points fondamentaux qu’il faut absolument souligner pour faire comprendre aux étudiants les fondements du thème étudié, les possibles digressions qui permettent d’élargir mon propos, les réactions attendues ou inattendues du public selon leur culture et leur parcours antérieur. En rédigeant l’article, je me suis rendu compte que ces éléments font tout le sel d’un exposé. Pour nous enseignants-chercheurs, il reste encore un petit espace pour les CM en présentiel devant les étudiants.
Document : Ricco Rakotomalala, « Ressources partagées – Introduction à l’apprentissage supervisé », Statistique et Enseignement, 8(2), 43-58, décembre 2017.
Antoine m’a proposé de faire un descriptif commenté d’un de mes supports de cours. Ca m’a un peu titillé l’esprit. Faire l’exégèse de son propre travail n’est jamais facile. J’ai eu un peu de mal à démarrer j’avoue, puis j’ai eu beaucoup de plaisir à le faire une fois lancé. Comme tout enseignant chercheur, je parle beaucoup durant un cours, sans y penser réellement de manière explicite en amont. J’aborde tout un tas de sujets en relation d’une part avec mon expérience ou même l’actualité, d’autre part avec le profil des étudiants que j’ai en face de moi. Heureusement d’ailleurs, sinon je ne vois pas très bien l’intérêt pour nous de faire des cours magistraux (CM), à ânonner béatement la même chose tous les ans en lisant les slides. Je pense même que l’interaction est la seule justification valable encore aujourd’hui de l’existence des CM. Autrement, il y a pléthore de supports sur le web, y compris des cours en vidéo très bien faits de collègues très compétents. Décalquer avec plus ou moins de bonheur ce que dit tout le monde n’a pas vraiment d’intérêt.
J’ai choisi de travailler sur mon support de cours dédié à l’Introduction de l’apprentissage supervisé. Il s’agit d’un CM crucial où j’essaie de faire appréhender aux étudiants les notions clés de l’analyse prédictive. Chaque slide est décrit de manière approfondie, avec les commentaires qui peuvent me venir à l’esprit, les points fondamentaux qu’il faut absolument souligner pour faire comprendre aux étudiants les fondements du thème étudié, les possibles digressions qui permettent d’élargir mon propos, les réactions attendues ou inattendues du public selon leur culture et leur parcours antérieur. En rédigeant l’article, je me suis rendu compte que ces éléments font tout le sel d’un exposé. Pour nous enseignants-chercheurs, il reste encore un petit espace pour les CM en présentiel devant les étudiants.
Document : Ricco Rakotomalala, « Ressources partagées – Introduction à l’apprentissage supervisé », Statistique et Enseignement, 8(2), 43-58, décembre 2017.
mardi 2 janvier 2018
Bonne année 2018 - Bilan 2017
L’année 2017 s’achève, 2018 commence. Je vous souhaite à tous une belle et heureuse année 2018.
Un petit bilan chiffré concernant l'activité organisée autour du projet Tanagra pour l'année écoulée. L'ensemble des sites (logiciel, support de cours, ouvrages, tutoriels) a été visité 222.293 fois en 2017, soit 609 visites par jour.
Il y a une forte diminution de la fréquentation par rapport à l’année dernière (721 visites par jours en 2016), dû en partie aux pannes répétées de notre serveur. Je m’en excuse auprès des internautes qui, pendant plusieurs périodes, n’ont pas pu accéder aux supports et tutoriels.
Depuis la mise en place du compteur Google Analytics (01 février 2008), le groupe de sites a été visité 2.333.371 fois, soit 644 visites par jour.
Les visiteurs viennent en majorité de la France (52%), du Maghreb (16%) et de l’Afrique francophone. Les pages de supports de cours ont toujours autant de succès, en particuliers ceux dédiés à la Data Science et à la programmation (R et Python).
39 supports de cours et tutoriels supplémentaires ont été postés cette année : 18 en français, 21 en anglais.
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d’Informatique.
Ricco.
Diaporama : Tanagra - Bilan 2017
Un petit bilan chiffré concernant l'activité organisée autour du projet Tanagra pour l'année écoulée. L'ensemble des sites (logiciel, support de cours, ouvrages, tutoriels) a été visité 222.293 fois en 2017, soit 609 visites par jour.
Il y a une forte diminution de la fréquentation par rapport à l’année dernière (721 visites par jours en 2016), dû en partie aux pannes répétées de notre serveur. Je m’en excuse auprès des internautes qui, pendant plusieurs périodes, n’ont pas pu accéder aux supports et tutoriels.
Depuis la mise en place du compteur Google Analytics (01 février 2008), le groupe de sites a été visité 2.333.371 fois, soit 644 visites par jour.
Les visiteurs viennent en majorité de la France (52%), du Maghreb (16%) et de l’Afrique francophone. Les pages de supports de cours ont toujours autant de succès, en particuliers ceux dédiés à la Data Science et à la programmation (R et Python).
39 supports de cours et tutoriels supplémentaires ont été postés cette année : 18 en français, 21 en anglais.
En cette nouvelle année, je souhaite le meilleur à tous les passionnés de Data Science, de Statistique et d’Informatique.
Ricco.
Diaporama : Tanagra - Bilan 2017
Inscription à :
Articles (Atom)